By 
Introduction
The main question about NOLOGGING I hear all the time is: does creating a table with the NOLOGGING option means there is “no generation of redo ever”, or just that the initial creation operation has no redo generation, but that DML down the road generates redo? How and when can the NOLOGGING option be employed?
Redo generation is a vital part of the Oracle recovery mechanism. Without it, an instance will not recover when it crashes and will not start in a consistent state. Excessive redo generation is the result of excessive work on the database.
This paper covers the subject of reducing redo generation using LOGGING and NOLOGGING options, the differences between them, how it happens, how to reduce it and when to use.
Also, you will find examples and tips regarding each one of them.
The main benefits of the NOLOGGING option suggested by the Oracle® Database Administrator’s Guide 10g Release 2 are:
-
Space is saved in the redo log files
-
The time it takes to create the table is decreased
-
Performance improves for parallel creation of large tables
“A very important rule with respect to data is to never put yourself into an unrecoverable situation. The importance of this guideline cannot be stressed enough, but it does not mean that you can never use time saving or performance enhancing options.“
What is a Redo?
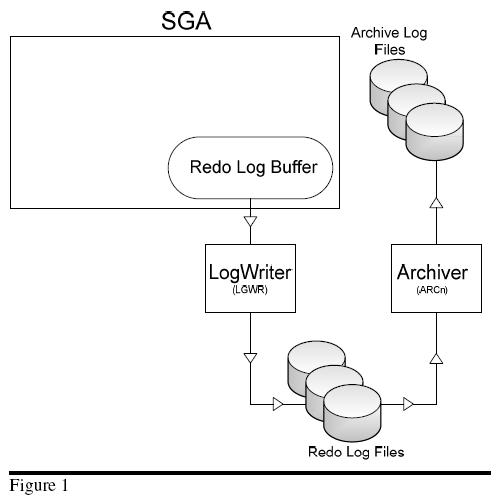
Let’s conduct a brief summary about the redo process. When Oracle blocks are changed, including undo blocks, oracle records the changes in a form of vector changes which are referred to as redo entries or redo records. The changes are written by the server process to the redo log buffer in the SGA. The redo log buffer is then flushed into the online redo logs in near real time fashion by the log writer LGWR. (See Figure 1)
The redo logs are written by the LGWR when:
- When a user issue a commit.
- When the Log Buffer is 1/3 full.
- When the amount of redo entries is 1MB.
- Every three seconds
- When a database checkpoint takes place. The redo entries are written before the checkpoint to ensure recoverability.
“If the log buffer is too small, then log buffer space waits will be seen during bursts of redo generation. LGWR may not begin to write redo until the _log_io_size threshold (by default, 1/3 of the log buffer or 1M whichever is less) has been exceeded, and the remainder of the log buffer may be filled before LGWR can complete its writes and free some space in the log buffer.
Ideally, the log buffer should be large enough to cope with all bursts of redo generation, without any log buffer space waits.
Commonly, the most severe bursts of redo generation occur immediately after a log switch, when redo generation has been disabled for some time, and there is a backlog of demand for log buffer space” by Steve Adams.
Redo log files record changes to the database as a result of transactions and internal Oracle server actions. (A transaction is a logical unit of work, consisting of one or more SQL statements run by a user.) Redo log files protect the database from the loss of integrity because of system failures caused by power outages, disk failures, and so on. Redo log files must be multiplexed to ensure that the information stored in them is not lost in the event of a disk failure. The redo log consists of groups of redo log files. A group consists of a redo log file and its multiplexed copies. Each identical copy is said to be a member of that group, and each group is identified by a number. The Log Writer (LGWR) process writes redo records from the redo log buffer to all members of a redo log group until the file is filled or a log switch operation is requested. Then, it switches and writes to the files in the next group. Redo log groups are used in a circular fashion (see figure 2).

Best practice tip:
Oracle recommends that redo log groups have at least two files per group, with the files distributed on separate disks or controllers so that no single equipment failure destroys an entire log group.
The loss of an entire log group is one of the most serious possible media failures because it can result in loss of data. The loss of a single member within a multiple-member log group is trivial and does not affect database operation, other than causing an alert to be published in the alert log.
Remember that redo logs heavily influence database performance because a commit cannot complete until the transaction information has been written to the logs. You must place your redo log files on your fastest disks served by your fastest controllers. If possible, do not place any other database files on the same disks as your redo log files. Because only one group is written to at a given time, there is no harm in having members from several groups on the same disk.
To avoid losing information that could be required to recover the database at some point, Oracle has an archive (ARCn) background process that archives redo log files when they become filled. However, it’s important to note not all Oracle Databases will have the archive process enabled. An instance with archiving enabled, is said to operate in ARCHIVELOG mode and an instance with archiving disabled is said to operate in NOARCHIVELOG mode.
You can determine with mode or if archiving is been used in your instance either by checking the value for the LOG_ARCHIVE_START parameter in your instance startup parameter file (pfile or spfile – This parameter is deprecated on version 10g), by issuing an SQL query to the v$database (“ARCHIVELOG” indicates archiving is enabled, and “NOARCHIVELOG” indicates that archiving is not enabled) or by issuing the SQL ARCHIVE LOG LIST command.
SQL> Select log_mode from v$database;
LOG_MODE
-------------------
ARCHIVELOG
SQL> archive log list
Database log mode Archive Mode
Automatic archival Enabled
Archive destination USE_DB_RECOVERY_FILE_DEST
Oldest online log sequence 8
Next log sequence to archive 10
Current log sequence 10
Wait for next part, I will talk about Redo Generation and Recoverability: how, when and why.
1 thought on “LOGGING or NOLOGGING, that is the question – Part I”